from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor()
# k-최근접 이웃 회귀 모델을 훈련합니다
knr.fit(train_input, train_target)
knr.score(test_input, test_target)
0.992809406101064
mean_absolute_error : 타깃과 예측의 절댓값 오차의 평균
from sklearn.metrics import mean_absolute_error
# 테스트 세트에 대한 예측을 만듭니다
test_prediction = knr.predict(test_input)
# 테스트 세트에 대한 평균 절댓값 오차를 계산합니다
mae = mean_absolute_error(test_target, test_prediction)
print(mae)
19.157142857142862
평균적으로 무게에 대한 예측 값과 실제 값이 19g정도 차이 난다는 결과
과대적합 vs 과소적합
과대적합(overfitting) : 훈련 세트만 점수가 좋고 테스트 세트에서 점수가 낮음
과소적합(underfitting) : 훈련세트보다 테스트세트의 점수가 더 높거나, 둘다 낮은 경우
print(knr.score(train_input, train_target))
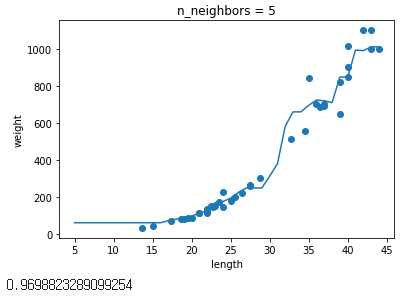
0.9698823289099254
knr.score(test_input, test_target) : 0.99
knr.score(train_input, train_target) : 0.96
훈련세트보다 테스트세트의 점수가 높으니 과소적합
# 이웃의 갯수를 3으로 설정
knr.n_neighbors = 3
# 모델을 다시 훈련
knr.fit(train_input, train_target)
print(knr.score(train_input, train_target))
0.9804899950518966
점수가 조금 더 올라 갔다
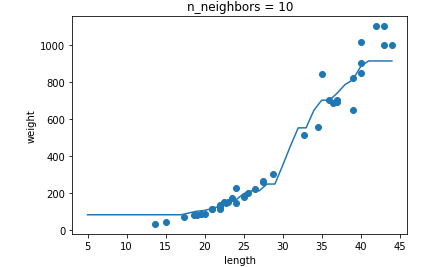
이웃 수를 변경하면서 결과를 확인해보자
# k-최근접 이웃 회귀 객체를 만듭니다
knr = KNeighborsRegressor()
# 5에서 45까지 x 좌표를 만듭니다
x = np.arange(5, 45).reshape(-1, 1)
# n = 1, 5, 10일 때 예측 결과를 그래프로 그립니다.
for n in [1, 5, 10]:
# 모델 훈련
knr.n_neighbors = n
knr.fit(train_input, train_target)
# 지정한 범위 x에 대한 예측 구하기
prediction = knr.predict(x)
# 훈련 세트와 예측 결과 그래프 그리기
plt.scatter(train_input, train_target)
plt.plot(x, prediction)
plt.title('n_neighbors = {}'.format(n))
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
print(knr.score(train_input, train_target))
# np.column_stack()은 2차 배열 방식으로 연결
# np.concatenate()은 1차 배열 방식으로 연결
# 1이 35개, 0이 14개 있는 data 생성
fish_target = np.concatenate((np.ones(35), np.zeros(14)))
print(fish_target)
## scikit-learn으로 training set, test set 나누기
# train_test_split() : training/test set를 fish_target에 맞게 나눠준다
# 기본적으로 25%를 test set으로 만든다
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
fish_data, fish_target, stratify=fish_target, random_state=42)
# shape : size를 표시
print(train_input.shape, test_input.shape)
print(train_target.shape, test_target.shape)
print(test_target)
(36, 2) (13, 2)
(36,) (13,)
[0. 0. 1. 0. 1. 0. 1. 1. 1. 1. 1. 1. 1.]
# 수상한 도미 한마리
# 이번 장의 핵심 주제 : 엉뚱한 결과로 들어가는 data를 어떻게 보정할 것인가?
# 기존 알고리즘 : 그냥 근접 이웃을 표시
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
kn.fit(train_input, train_target)
kn.score(test_input, test_target)
print(kn.predict([[25, 150]]))