결정트리: yes/no로 구분하여 트리로 답을 찾는 알고리즘, 이해하기 쉽고 성능도 뛰어남
불순도: 결정트리가 최적의 질문을 찾기 위한 기준. sklearn은 gini불순도와 엔트로피 불순도를 제공
정보이득: 부도 노드와 자식 노드의 불순도 차이. 결정 트리 알고리즘은 정보 이득이 최대화 되도록 학습
- 결정트리는 제한 없이 성장하면 훈련세트에 과대적합되기 쉬움.
- 가지치기는 결정트리의 성장을 제한하는 방법
특성 중요도: 결정트리에 사용된 특성이 불순도를 감소하는데 기여한 정도
결정 트리
로지스틱 회귀로 와인 분류하기
import pandas as pd
wine = pd.read_csv('https://bit.ly/wine_csv_data')
wine.head()
wine.info()
info() 함수는 누락된 내용이 있는지 파악하는데 용이함
총 6497 entries중 non-null이 모두 6497이므로 누락된 내용은 없음
누락된 값이 있다면 그 data를 버리거나 평균 값으로 채워 넣어야 한다.

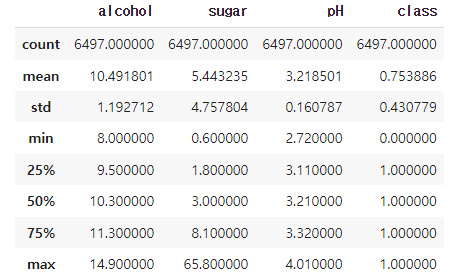
wine.describe()describe()는 간단한 통계를 보여 준다.
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
data, target, test_size=0.2, random_state=42)
print(train_input.shape, test_input.shape)(5197, 3) (1300, 3)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
#로지스틱으로 계산을 해본다
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target))
print(lr.score(test_scaled, test_target))0.7808350971714451
0.7776923076923077
훈련세트(0.78), 테스트세트(0.77)로 과소적합
print(lr.coef_, lr.intercept_)[[ 0.51270274 1.6733911 -0.68767781]] [1.81777902]
결정 트리
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))0.996921300750433
0.8592307692307692
로지스틱보다 나은 결과가 나왔지만 훈련세트가 0.99로 아주 높고 테스트세트가 0.85로 낮아 과대적합이다.
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(10,7))
plot_tree(dt)
plt.show()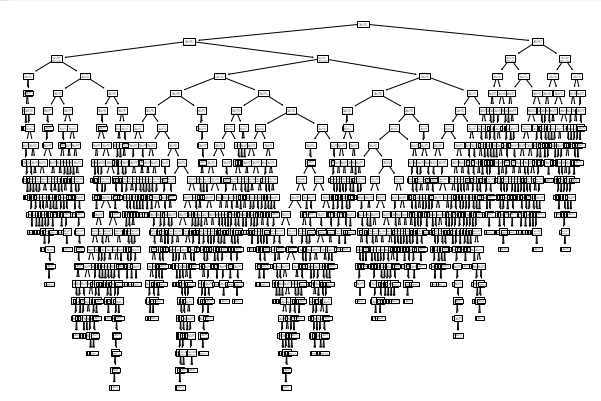
depth가 너무 깊어 과대적합이 되었다. 이를 제한하여 어떻게 결정되었는지 알아보자
plt.figure(figsize=(10,7))
plot_tree(dt, max_depth=1, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()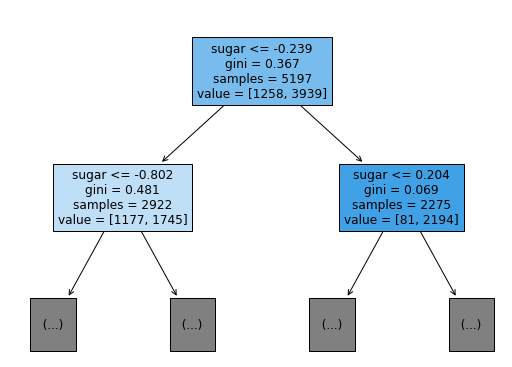
가지치기
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))0.8454877814123533
0.8415384615384616
max_depth를 5로 할 때 더 좋은 결과가 나왔는데 조건을 확인하기가 어려웠다
plt.figure(figsize=(20,15))
plot_tree(dt, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()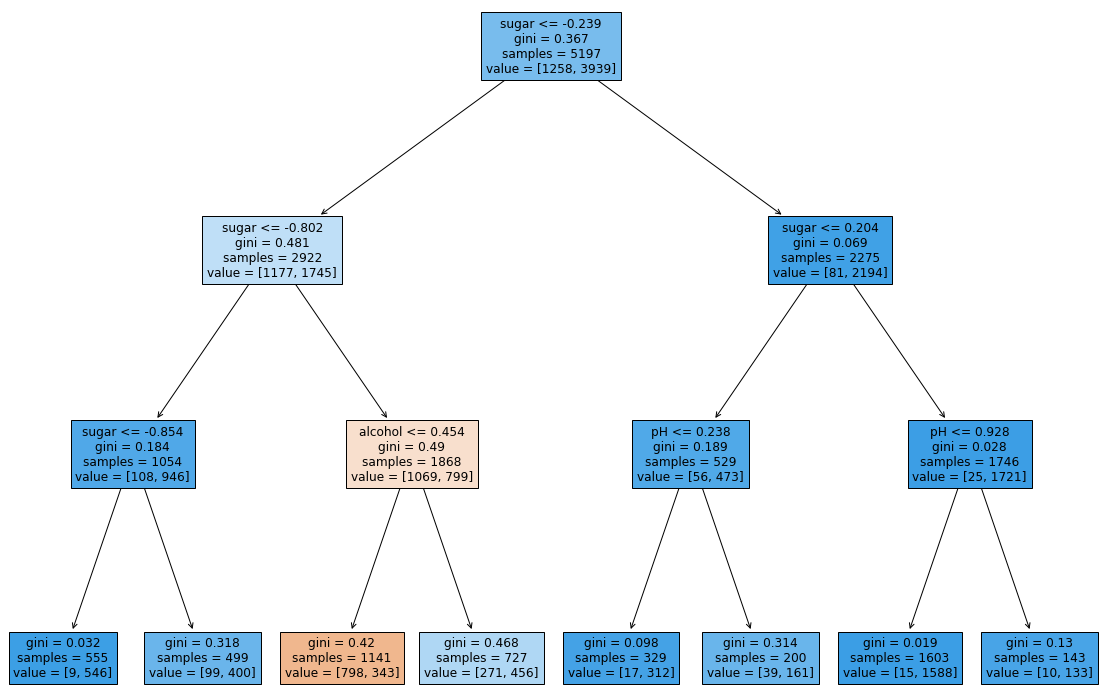
조건 식의 값들이 일반적으로 알기 어려운 숫자들이다. 이는 전처리를 거쳤기 때문으로 전처리 되지 않은 자료를 다시 넣고 결과를 확인해보자.
data에 대한 전처리가 필요하지 않다는 것이 결정 트리 알고리즘의 장점 중 하나
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_input, train_target)
print(dt.score(train_input, train_target))
print(dt.score(test_input, test_target))0.8454877814123533
0.8415384615384616
plt.figure(figsize=(20,15))
plot_tree(dt, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()
당도(sugar)가 4.325 이하, 1.625 이상이면서 alcohol이 11.025 이하면 red wine으로 인식하고 나머지는 white wine으로 인식
print(dt.feature_importances_)[0.12345626 0.86862934 0.0079144 ]
'Programming > Machine Learning' 카테고리의 다른 글
| [혼공머신] 용어 04장 (0) | 2022.02.28 |
|---|---|
| [혼공머신] 06-2 k-평균 (0) | 2022.02.20 |
| [혼공머신] 06-1 군집 알고리즘(비지도학습) (0) | 2022.02.19 |
| [혼공머신] 05-3 트리의 앙상블 (0) | 2022.02.13 |
| [혼공머신] 05-2 교차 검증과 그리드 서치 (0) | 2022.02.12 |
| [혼공머신] 04-2 확률적 경사 하강법 (0) | 2022.02.05 |
| [혼공머신] 용어 03장 (0) | 2022.02.03 |
| [혼공머신] 04-1 로지스틱 회귀 (0) | 2022.01.23 |
| [혼공머신] 03-3 특성공학과 규제 (0) | 2022.01.22 |
| [혼공머신] 03-2 선형 회귀 (0) | 2022.01.16 |